



🔑 Get Your API Key (100 free credits) • 📖 Full Documentation • 💬 Support
⚡ Now with Async Support! • 🚀 Up to 40x Faster • 🎯 Production Ready
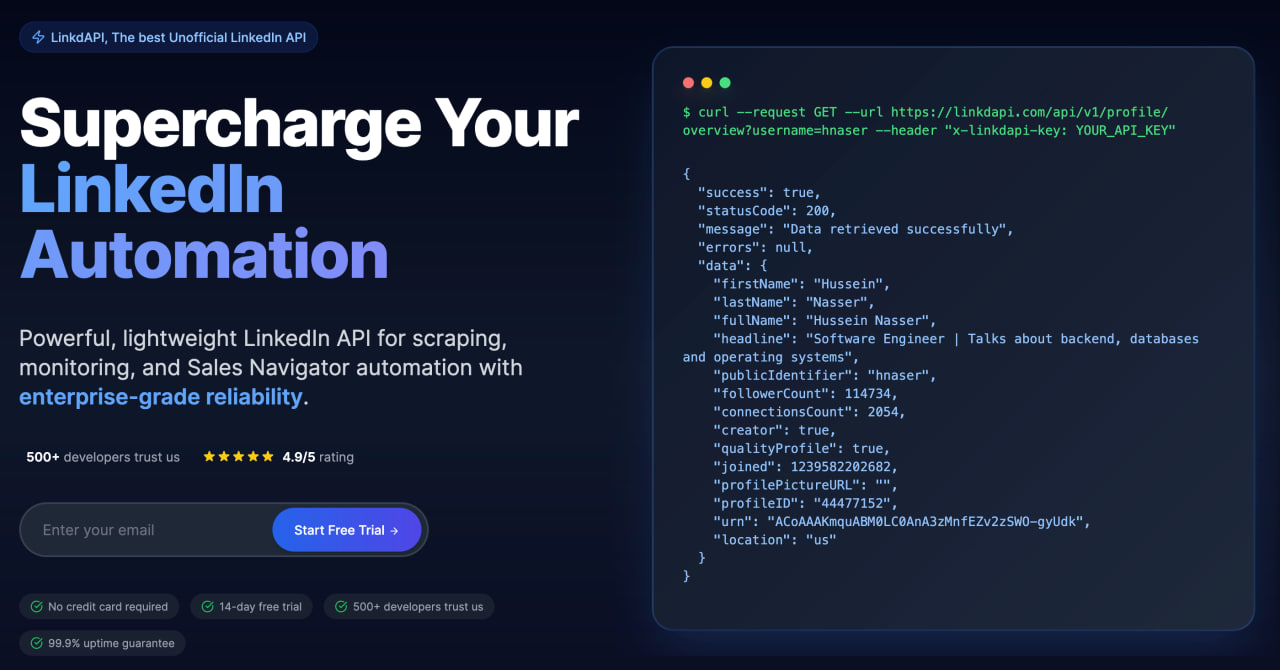
A lightweight Python wrapper for LinkdAPI — the most advanced unofficial LinkedIn API you'll ever find. Instead of relying on brittle scrapers or search engine hacks, LinkdAPI connects straight to LinkedIn's own mobile and web endpoints. That means you get access to real-time data with unmatched reliability, stability, and scalability — perfect for developers, analysts, and anyone building tools that tap into LinkedIn at scale.
- Why LinkdAPI?
- Why LinkdAPI Beats Alternatives
- 📦 Installation
- ✨ Key Features
- 🚀 Quick Start
- ⚡ Performance Benefits
- 📚 API Reference
- 💡 Real-World Examples
- 📈 Use Cases
- 🔧 Error Handling
- 🔗 Resources
- 📜 License
- We do not rely on search engines or SERP scraping – all data is retrieved directly from LinkedIn.
- Built for scale, stability, and accuracy using direct endpoints.
- Ideal for automation, data extraction, reverse lookup, and lead generation.
| Feature | LinkdAPI | SerpAPI | Scraping |
|---|---|---|---|
| Direct LinkedIn Access | ✅ Yes | ❌ No | ❌ No |
| No Proxy Management | ✅ Yes | ❌ No | ❌ No |
| No Cookies Management | ✅ Yes | ❌ No | ❌ No |
| Structured JSON Data | ✅ Yes | ❌ HTML | ✅ Yes |
| Scalability | ✅ Built for scale | ❌ Rate-limited | ❌ Manual effort |
| Pricing Transparency | ✅ Clear pricing tiers | ✅ Pay-per-request | ❌ Hidden costs (proxies, CAPTCHAs) |
| API Reliability | ✅ High uptime | ✅ Good | ❌ Unstable (blocks) |
| Automation-Friendly | ✅ Full automation | ✅ Partial | ❌ Manual work needed |
| Support & Documentation | ✅ Dedicated support | ✅ Good docs | ❌ Community-based |
| Anti-Blocking | ✅ Built-in evasion | ❌ N/A | ❌ High risk |
Install with pip:
pip install linkdapi
|
|
from linkdapi import LinkdAPI
# Initialize the client
client = LinkdAPI("your_api_key")
# Get profile overview
profile = client.get_profile_overview("ryanroslansky")
print(f"Profile: {profile['data']['fullName']}")
# Get company information
company = client.get_company_info(name="linkedin")
print(f"Company: {company['data']['name']}")For better performance with multiple requests, use the async client:
import asyncio
from linkdapi import AsyncLinkdAPI
async def main():
# Use async context manager (recommended)
async with AsyncLinkdAPI("your_api_key") as api:
# Single request
profile = await api.get_profile_overview("ryanroslansky")
print(f"Profile: {profile['data']['fullName']}")
# Fetch multiple profiles concurrently
profiles = await asyncio.gather(
api.get_profile_overview("ryanroslansky"),
api.get_profile_overview("satyanadella"),
api.get_profile_overview("jeffweiner08")
)
for profile in profiles:
print(f"Name: {profile['data']['fullName']}")
# Run the async function
asyncio.run(main())import asyncio
from linkdapi import AsyncLinkdAPI
async def fetch_profile_data(username: str):
"""Fetch complete profile data including posts and connections."""
async with AsyncLinkdAPI("your_api_key") as api:
# Get profile overview first
overview = await api.get_profile_overview(username)
urn = overview['data']['urn']
# Fetch multiple endpoints concurrently
results = await asyncio.gather(
api.get_profile_details(urn),
api.get_full_experience(urn),
api.get_education(urn),
api.get_skills(urn),
return_exceptions=True # Handle errors gracefully
)
return {
"overview": overview,
"details": results[0],
"experience": results[1],
"education": results[2],
"skills": results[3]
}
# Usage
data = asyncio.run(fetch_profile_data("ryanroslansky"))The async client provides significant performance improvements when making multiple API calls:
| Scenario | Sync Client | Async Client | Improvement |
|---|---|---|---|
| Single Request | ~200ms | ~200ms | Same |
| 10 Sequential Requests | ~2000ms | ~2000ms | Same |
| 10 Concurrent Requests | ~2000ms | ~200ms | 10x faster |
| 100 Concurrent Requests | ~20000ms | ~500ms | 40x faster |
When to use Async:
- ✅ Scraping multiple profiles at once
- ✅ Batch processing jobs or companies
- ✅ Real-time data aggregation
- ✅ Building high-performance APIs
When to use Sync:
- ✅ Simple scripts
- ✅ Single requests
- ✅ Learning/prototyping
All methods are available in both LinkdAPI (sync) and AsyncLinkdAPI (async) classes.
🔹 Profile Endpoints (Click to expand)
# Profile Information
get_profile_overview(username) # Basic profile info
get_profile_details(urn) # Detailed profile data
get_contact_info(username) # Email, phone, websites
get_profile_about(urn) # About section & verification
# Work & Education
get_full_experience(urn) # Complete work history
get_certifications(urn) # Professional certifications
get_education(urn) # Education history
get_skills(urn) # Skills & endorsements
# Social & Engagement
get_social_matrix(username) # Connections & followers count
get_recommendations(urn) # Given & received recommendations
get_similar_profiles(urn) # Similar profile suggestions
get_profile_reactions(urn, cursor='') # All profile reactions
get_profile_interests(urn) # Profile interests🔹 Company Endpoints (Click to expand)
# Company Search & Info
company_name_lookup(query) # Search companies by name
get_company_info(company_id=None, name=None) # Get company details
get_similar_companies(company_id) # Similar company suggestions
get_company_employees_data(company_id) # Employee statistics
get_company_jobs(company_ids, start=0) # Active job listings
get_company_affiliated_pages(company_id) # Subsidiaries & affiliates🔹 Job Endpoints (Click to expand)
# Job Search
search_jobs(
keyword=None, # Job title, skills, or keywords
location=None, # City, state, or region
geo_id=None, # LinkedIn geographic ID
company_ids=None, # Specific company IDs
job_types=None, # full_time, part_time, contract, etc.
experience=None, # internship, entry_level, mid_senior, etc.
regions=None, # Region codes
time_posted='any', # any, 24h, 1week, 1month
salary=None, # any, 40k, 60k, 80k, 100k, 120k
work_arrangement=None, # onsite, remote, hybrid
start=0 # Pagination
)
# Job Details
get_job_details(job_id) # Detailed job information
get_similar_jobs(job_id) # Similar job postings
get_people_also_viewed_jobs(job_id) # Related jobs🔹 Post Endpoints (Click to expand)
# Posts
get_featured_posts(urn) # Featured posts
get_all_posts(urn, cursor='', start=0) # All posts with pagination
get_post_info(urn) # Single post details
get_post_comments(urn, start=0, count=10, cursor='') # Post comments
get_post_likes(urn, start=0) # Post likes/reactions🔹 Comment Endpoints (Click to expand)
get_all_comments(urn, cursor='') # All comments by profile
get_comment_likes(urns, start=0) # Likes on specific comments🔹 Search Endpoints (Click to expand)
# People Search
search_people(
keyword=None,
current_company=None,
first_name=None,
geo_urn=None,
industry=None,
last_name=None,
profile_language=None,
past_company=None,
school=None,
title=None,
start=0
)
# Company Search
search_companies(
keyword=None,
geo_urn=None,
company_size=None,
has_jobs=None,
industry=None,
start=0
)
# Post Search
search_posts(
keyword=None,
author_company=None,
author_industry=None,
content_type=None,
date_posted=None,
from_member=None,
sort_by='relevance',
start=10
)
# Other Search
search_services(keyword=None, geo_urn=None, start=0)
search_schools(keyword=None, start=0)🔹 Article Endpoints (Click to expand)
get_all_articles(urn, start=0) # All articles by profile
get_article_info(url) # Article details from URL
get_article_reactions(urn, start=0) # Article likes/reactions🔹 Lookup Endpoints (Click to expand)
geo_name_lookup(query) # Search locations & get geo IDs
title_skills_lookup(query) # Search skills & job titles
services_lookup(query) # Search service categories🔹 System (Click to expand)
get_service_status() # Check API service status📖 Full documentation for all endpoints: linkdapi.com/docs
🚀 More endpoints coming soon! Check our roadmap
import asyncio
from linkdapi import AsyncLinkdAPI
async def enrich_leads(usernames: list):
"""Enrich a list of LinkedIn usernames with profile data."""
async with AsyncLinkdAPI("your_api_key") as api:
# Fetch all profiles concurrently
tasks = [api.get_profile_overview(username) for username in usernames]
profiles = await asyncio.gather(*tasks, return_exceptions=True)
enriched_data = []
for username, profile in zip(usernames, profiles):
if isinstance(profile, dict) and profile.get('success'):
data = profile['data']
enriched_data.append({
'username': username,
'name': data.get('fullName'),
'headline': data.get('headline'),
'location': data.get('location'),
'company': data.get('company')
})
return enriched_data
# Process 100 leads in seconds instead of minutes
leads = ['ryanroslansky', 'satyanadella', 'jeffweiner08', ...]
data = asyncio.run(enrich_leads(leads))import asyncio
from linkdapi import AsyncLinkdAPI
async def get_company_intelligence(company_name: str):
"""Get comprehensive company data for analysis."""
async with AsyncLinkdAPI("your_api_key") as api:
# Get company info
company_info = await api.get_company_info(name=company_name)
company_id = company_info['data']['id']
# Fetch multiple data points concurrently
results = await asyncio.gather(
api.get_company_employees_data(company_id),
api.get_similar_companies(company_id),
api.get_company_jobs(company_id),
api.get_company_affiliated_pages(company_id),
return_exceptions=True
)
return {
'info': company_info,
'employees': results[0],
'similar': results[1],
'jobs': results[2],
'affiliates': results[3]
}
intelligence = asyncio.run(get_company_intelligence("linkedin"))from linkdapi import AsyncLinkdAPI
import asyncio
async def analyze_job_market(role: str, locations: list):
"""Analyze job market across multiple locations."""
async with AsyncLinkdAPI("your_api_key") as api:
# Search jobs in multiple locations concurrently
tasks = [
api.search_jobs(keyword=role, location=location, time_posted='1week')
for location in locations
]
results = await asyncio.gather(*tasks)
analysis = {}
for location, result in zip(locations, results):
if result.get('success'):
jobs = result['data']['jobs']
analysis[location] = {
'total_jobs': len(jobs),
'companies': list(set([j['company'] for j in jobs])),
'salary_range': [j.get('salary') for j in jobs if j.get('salary')]
}
return analysis
# Analyze "Software Engineer" jobs across 5 cities in parallel
analysis = asyncio.run(analyze_job_market(
"Software Engineer",
["San Francisco, CA", "New York, NY", "Austin, TX", "Seattle, WA", "Boston, MA"]
))
|
|
Both sync and async clients provide robust error handling:
import httpx
from linkdapi import AsyncLinkdAPI
async def fetch_with_error_handling():
async with AsyncLinkdAPI("your_api_key") as api:
try:
profile = await api.get_profile_overview("username")
if profile.get('success'):
print(f"Success: {profile['data']}")
else:
print(f"API Error: {profile.get('message')}")
except httpx.HTTPStatusError as e:
# Handle HTTP errors (4xx, 5xx)
print(f"HTTP Error {e.response.status_code}: {e.response.text}")
except httpx.RequestError as e:
# Handle network errors
print(f"Network Error: {str(e)}")
except Exception as e:
# Handle unexpected errors
print(f"Unexpected Error: {str(e)}")The async client automatically retries failed requests with exponential backoff:
# Configure retry behavior
async with AsyncLinkdAPI(
api_key="your_api_key",
max_retries=5, # Default: 3
retry_delay=2.0, # Default: 1.0 seconds
timeout=60.0 # Default: 30.0 seconds
) as api:
# Requests will be retried automatically on failure
profile = await api.get_profile_overview("username")LinkdAPI is more than just an API wrapper—it's a complete solution for LinkedIn data extraction:
- Async/Await Support - Up to 40x faster for batch operations
- Connection Pooling - Efficient resource management
- Smart Retries - Automatic recovery from transient failures
- Type Safety - Full type hints for better IDE support
- Error Recovery - Comprehensive error handling and retries
- Battle Tested - Used by developers worldwide
- Dual APIs - Choose sync or async based on your needs
- Context Managers - Proper resource cleanup
- Rich Documentation - Examples for every use case
Whether you're building a high-performance LinkedIn data extractor, a comprehensive LinkedIn profile scraper, or automated recruiting tools, LinkdAPI delivers the power, reliability, and speed you need—without the complexity of traditional scraping.
MIT License – Free to use for personal and commercial projects.
If you find LinkdAPI useful, consider:
- ⭐ Starring the project on GitHub
- 🐦 Following us on Twitter/X
- 📢 Sharing with your network
- 💡 Contributing ideas and feedback
Built with ❤️ for developers who need reliable LinkedIn data
Website • Documentation • Twitter • Support