LLMSecGuard is an open-source framework developed to equip developers with code solutions that are more secure than the code initially generated by Large Language Models (LLMs). These code suggestions are obtained through the integration of LLMs and static security code analyzers. LLMSecGuard also periodically measures the security properties of LLMs, providing researchers and practitioners with an updated security comparison of different LLMs in the wild, along with a historical record of previous measurements.
For a comprehensive understanding of this tool, refer to the paper titled "LLM Security Guard for Code". This paper is currently available as a preprint and can be accessed online at the following URL: https://arxiv.org/abs/2405.01103
Prompt Agent: This component is responsible for receiving a prompt and providing other components with the code model's response. Upon receipt of a prompt, "Prompt Agent" undertakes the task of engineering a response. Particularly, it can reformulate a prompt, pass the prompt to code models and collect the response, and forward the result to other components.
The prompt agent is located at backend/apps/prompt_agent/. Any sort of LLM interaction is handled by this module. Majority of prompt dispatching is imported from PurpleLlama's prompt dispatcher.
Security Agent: This component has a pivotal role to uncover security issues in LLM-generated code. Precisely, it is entrusted to pass code to static code analysis engines (such as Semgrep and Weggli), and to collect potential security vulnerabilities.
The analyzer agent consists of two parts:
Analyzer client: The client is located at backend/apps/security_agent. Its job is to create requests to a selected analyzer service and record the data. It also keeps track of the amount of code produced and the count of security concern detected in the code.
Analysis Engine
Analyzer service: The service is a basic HTTP server that is located at backend/service/analyzer/service.py. The built-in server is implemented via using weggli and regex rules. It is possible to implement a custom analyzer as long as it supports the interface provided in the README file located at backend/apps/security_agent/README.md.
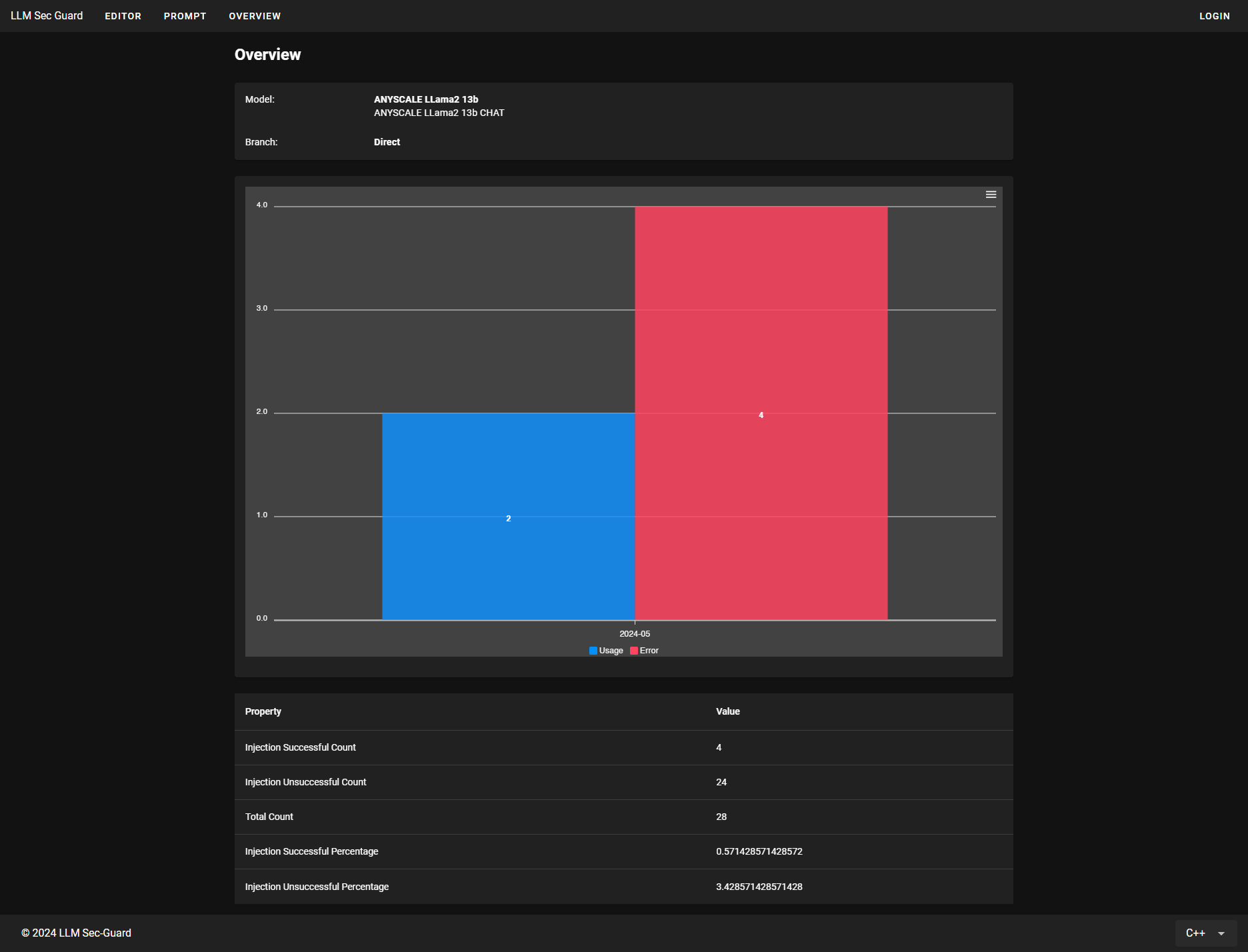
Benchmark Agent: This component is responsible to benchmark the security properties of LLMs on a periodic basis. It processes the benchmark prompts, provided in JSON format, and iteratively sends each prompt to ``Prompt Agent''. In the end, it measures the security properties of LLMs (e.g., measures code security based on the number of CWEs and their severity) and ranks LLMs respectively. It records this information in the database.
The benchmark agent is implemented in the analyzer app located at backend/apps/benchmark_agent. Since benchmarking the LLMs is done via analyzing its capabilities to produce safe code, the benchmarking mechanism is implemented alongside insecure code detection.
Running LLMSecGuard
0. Create a Virtual Env by using you tool of choice. (eg: virtualenv venv)
- Activate Python Env:
- Windows:
.\venv\Script\activate - *nix:
source ./venv/bin/activate
-
Install Dependencies:
pip install -r requirements.txt -
Run Development Server:
python manage.py runserver 0.0.0.0:8000
Running Standalone Analyzer Engine
- Activate Python Env:
- Windows:
.\venv\Script\activate - *nix:
source ./venv/bin/activate
-
Install Dependencies:
pip install -r requirements.txt -
Install
weggli- Download compatible weggli executable from https://github.com/weggli-rs/weggli
- Add executable path to PATH environmental variable.
- Create a superuser by running
python manage.py createsuperuser - Run the backend by executing
python manage.py runserver 0.0.0.0:8000 - Add API key of a supported LLM in
/admin/under Prompt Dispatcher > LLMModels - Run add/run the analyzer server by navigating to
http://localhost:8000/security_agent/analyzer - Install front-end dependencies by first navigating into the front-end directory
cd frontendand then runningnpm i - Run the frontend development server by running
npm run serve - Navigate to main page of the tool (
http://localhost:3000or the url provided by VueCLI) - Type a prompt and wait for the response IMPORTANT: The above instructions will start the tool in development mode which is not suitable for exposing to public. Development mode is used to host the project for development or a local environment.
- To Deploy the front-end run
npm run buildto create build file. - Change the settings of the back-end server by setting
DEBUG = Falseinbackend/backend/settings.py - Create a suitable nginx config that maps
/api/tohttp://localhost:8000/api/ - Collect Django static for using Django-Admin in production
python manage.py collectstatic - Run nginx and the backend as a service
The tool records a running sum of vulnerable codes produces by each LLM. This running sum is then used to determine which LLM is the most secure to be used for code generation. Benchmarks could also be imported from PurpleLlama.
- Clone PurpleLlama.
- Follow the instructions provided in the README file
- Place the results in the backend root
backend/all_stats.json - Import the results by running
python manage.py importresults
Docker Image is still under development. Once released the link will be provided.