A lightweight, production-ready PyTorch implementation of the Mixture of Recursions architecture from NeurIPS 2025.
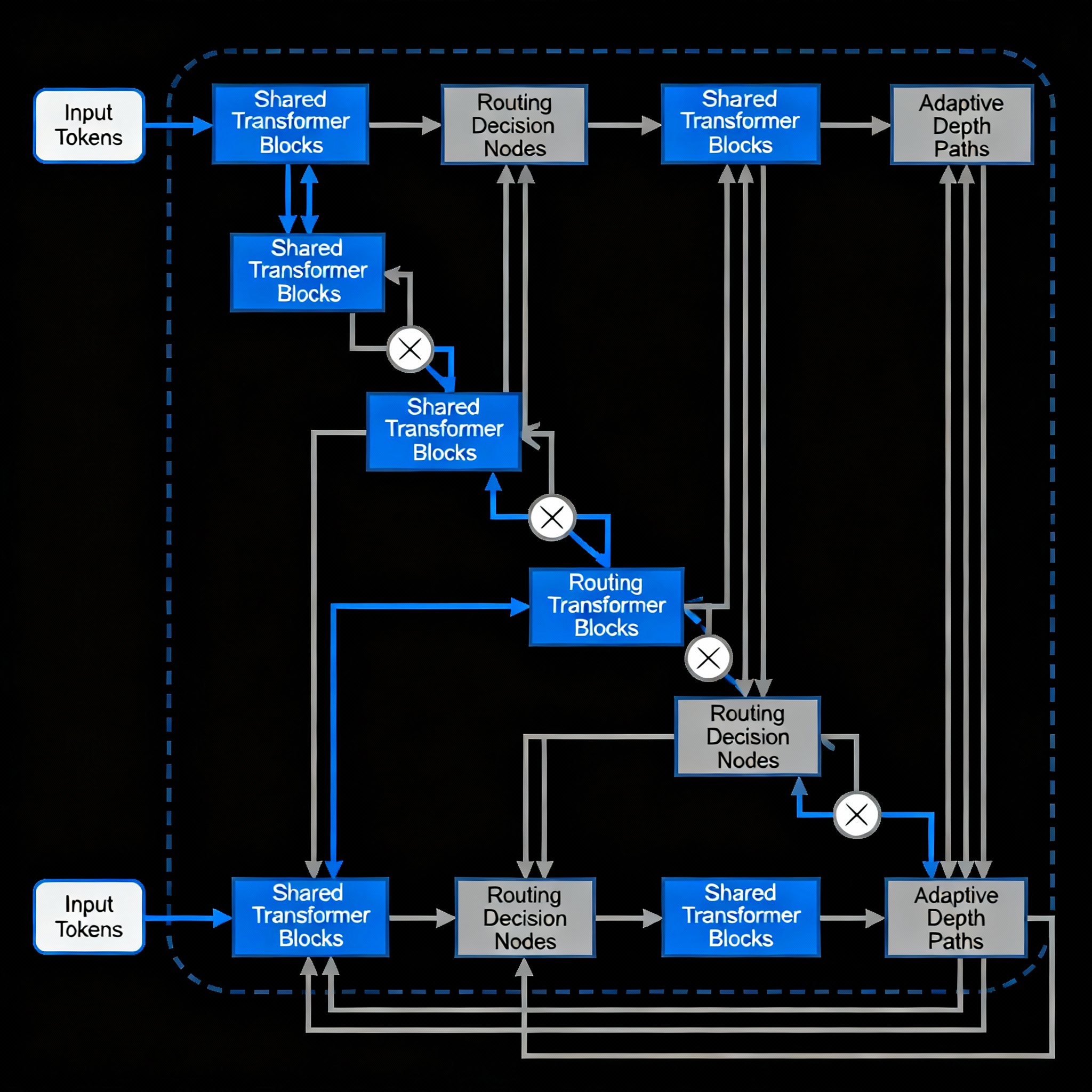
Mixture of Recursions (MoR) is an innovative transformer architecture that dynamically adjusts computational depth per token through learned routing mechanisms. This implementation provides both Expert-Choice and Token-Choice routing strategies in a clean, modular framework.
The official MoR codebase is powerful but quite large — making it difficult to run locally and challenging to follow for new users. This project simplifies the core ideas behind MoR, the dynamic recursion depths, parameter sharing, and adaptive token-level computation, into a lightweight and accessible package. It’s designed to make experimenting with, visualizing, and extending MoR models easy on standard hardware, making it ideal for learning, prototyping, and research.
- Two Routing Strategies: Expert-Choice and Token-Choice routing implementations
- Built-in Analysis: Comprehensive routing pattern visualization and analysis tools
- Research-Ready: Extensible architecture for novel research directions
- Efficient: Optimized for both research and practical applications
- Well-Documented: Extensive documentation and examples
- How it works: Each recursion level (expert) selects top-k tokens to process
- Benefits: Dynamic capacity allocation, sparse computation
- Use case: When you want experts to specialize in different token types
- How it works: Each token chooses its own recursion depth
- Benefits: Token-level adaptive computation, direct depth control
- Use case: When tokens have varying complexity requirements
# Clone and install
git clone https://github.com/Rohityalavarthy/mixture_of_recursions_sandbox.git
cd mixture-of-recursions
pip install -r requirements.txt
# Run demo comparing both routing strategies
python scripts/demo.pyfrom mor import SimpleMoRModel, SyntheticDataGenerator
# Expert-Choice Model
expert_model = SimpleMoRModel(
vocab_size=1000,
hidden_size=256,
num_classes=4,
num_layers=4,
num_recursions=3,
mor_type="expert_choice",
capacity_factor=0.8
)
# Token-Choice Model
token_model = SimpleMoRModel(
vocab_size=1000,
hidden_size=256,
num_classes=4,
num_layers=4,
num_recursions=3,
mor_type="token_choice",
alpha=0.1
)
# Generate data and train
data_gen = SyntheticDataGenerator(vocab_size=1000, max_seq_len=64)
train_loader = data_gen.create_dataloader("pattern", num_samples=1000, batch_size=32)
# Forward pass
for inputs, labels in train_loader:
expert_logits = expert_model(inputs)
token_logits = token_model(inputs)
break# Each recursion level selects tokens to process
for recursion_level in range(num_recursions):
router_scores = router(hidden_states) # Score all tokens
top_k_tokens = select_top_k(router_scores, capacity_factor) # Expert chooses tokens
processed = recursion_block(top_k_tokens) # Process selected tokens
output = scatter_add(processed, original_positions) # Merge back# Each token selects its recursion depth
router_logits = router(hidden_states) # (batch, seq_len, num_recursions)
token_assignments = argmax(router_logits, dim=-1) # Each token picks depth
for depth in range(num_recursions):
depth_mask = (token_assignments == depth) # Find tokens at this depth
processed = process_through_depth(hidden_states, depth) # Process through depth
output[depth_mask] = processed[depth_mask] # Update assigned tokens| Parameter | Expert-Choice | Token-Choice | Description |
|---|---|---|---|
mor_type |
"expert_choice" |
"token_choice" |
Routing strategy |
capacity_factor |
0.5-1.0 | N/A | Expert capacity (expert-choice only) |
alpha |
0.01-0.1 | 0.1-1.0 | Routing strength/temperature |
num_recursions |
2-5 | 2-5 | Maximum recursion depth |
Test both routing strategies on three built-in tasks:
# 1. Copy Task - Find and copy subsequences
train_loader = data_gen.create_dataloader("copy", num_samples=1000, copy_length=10)
# 2. Counting Task - Count token occurrences
train_loader = data_gen.create_dataloader("counting", num_samples=1000, target_token=42)
# 3. Pattern Recognition - Identify sequence patterns
train_loader = data_gen.create_dataloader("pattern", num_samples=1000)# Compare routing strategies
from mor.train import analyze_routing_patterns
expert_stats = analyze_routing_patterns(expert_model, val_loader)
token_stats = analyze_routing_patterns(token_model, val_loader)
print(f"Expert-Choice entropy: {expert_stats['mean_entropy']:.4f}")
print(f"Token-Choice entropy: {token_stats['mean_entropy']:.4f}")- Token specialization: When you want experts to learn token-type specialization
- Sparse computation: For efficient processing of large sequences
- Hierarchical patterns: When different recursion levels should handle different complexity
- Adaptive depth: When tokens have intrinsically different complexity needs
- Interpretability: Easier to understand which tokens need more computation
- Dynamic allocation: When computation requirements vary significantly per token
- Expert-Choice: Tune
capacity_factor(0.5-1.0) to balance computation and performance - Token-Choice: Adjust
alpha(0.1-1.0) to control routing sharpness - Both: Start with
num_recursions=3and adjust based on task complexity - Memory: Use smaller
hidden_sizeand batch sizes for large models
-
Inspired by Google DeepMind & university collaborations (see original paper)
-
Original Paper: Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation (NeurIPS 2025)
@software{mixture_of_recursions_sandbox,
author = {Rohit Yalavarthy},
title = {Mixture of Recursions: Sandbox},
year = {2025},
url = {https://github.com/Rohityalavarthy/mixture_of_recursions_sandbox.git}
}MIT License - see LICENSE for details.
Research with adaptive computation - Expert-Choice vs Token-Choice routing strategies!